Pitforge Raiding & Cannoning Update


Hello, Adventurers,
This post may only interest a small part of the player base, but since raiding is a core aspect of factions — and Pitforge has never been particularly raiding-friendly — we felt it was time to make some improvements. After all, Pitforge is a factions server, not a skyblock server. Today, we’ll talk about the changes we’re making to raiding.
Balancing & Core Design
In this section, I’ll go over some of the changes we’ve already teased, as well as introduce some we haven’t discussed yet.
Faction Plots & Raiding Overhaul
Raiding on Pitforge has received a complete overhaul! Highlights include:
- Raiding Limits: Limited lives during raids for both attackers and defenders.
- Allies: One ally faction can now support you whilst being raided.
- Raid Shop: Earn Energy Crystals and spend them on raid goodies.
- Faction-Rewind: Bases can be automatically restored (excluding tile states, like chest contents) after raids for a fee.
- New Plots: Modern design, 201x201 build area (double the old size) with a larger raid zone.
📖 You can read the full details here: Pitforge Summer Update

We will also not enforce any defense limitations such as a regen limit. Some defenses that we consider unbalanced will be banned, but we’ll be very generous in that regard.
Other changes include:
- Custom TNT/Creepers
- Faction Upgrades with Raiding mechanics
- New Cannoning mechanics introduced in newer versions
... And some other changes I do not want to reveal just yet.
Cannoning Physics
Okay so now let's get to the cool stuff. It's gonna get a little technical here, so if you're not into cannoning you can probably skip this section. I am gonna go over a few of the things that made cannoning terrible in the latest versions (even worse than on the original Pitforge, which was running on 1.12.2) and what we did to fix and/or balance them, giving you a deep technical insight into minecraft and it's cannoning physics.
Collision fixes
Whilst playing around with cannons in the latest version, I found myself with tnt and sand often just sliding off to the side when they should not have any velocity in that direction. It looked like somehow paper's collision logic was leaving a velocity component “alive” and causing glide.
So I went a head and implemented a more lightweight version of per-axis swept AABB collision checking, just for falling blocks and TNT. For each axis, I advance the box by its velocity, check for overlaps, and clamp the displacement to the first contact on that axis with a little epsilon. Then I repeat for the remaining axes (this is also where the east/west patch is in place. It's really just a simple algorithm determining which axis to prioritize). Besides some VoxelShape hassle, it's as simple as that. Simple, fast, and good enough for these objects. Paper currently uses an "optimized" version of this algorithm, which was the root cause for the described issues.
The Math behind it

Where
- v = (vx, vy, vz): your intended motion per step.
- If you treat v as velocity, the intended displacement is d = v * dt (velocity times time-step).
- If you already store “delta movement per tick,” then v is the same as d.
- s_x, s_y, s_z: the clamped displacement (delta) along each axis (x, y, z) after checking collisions on that axis.
- epsilon: just a tiny bias to prevent re-penetration due to floating-point error.
- N: the set of nearby blocking shapes (voxel/block collision shapes) you test against.
And a oversimplified 2D visualization of what's going on for the less mathematical people
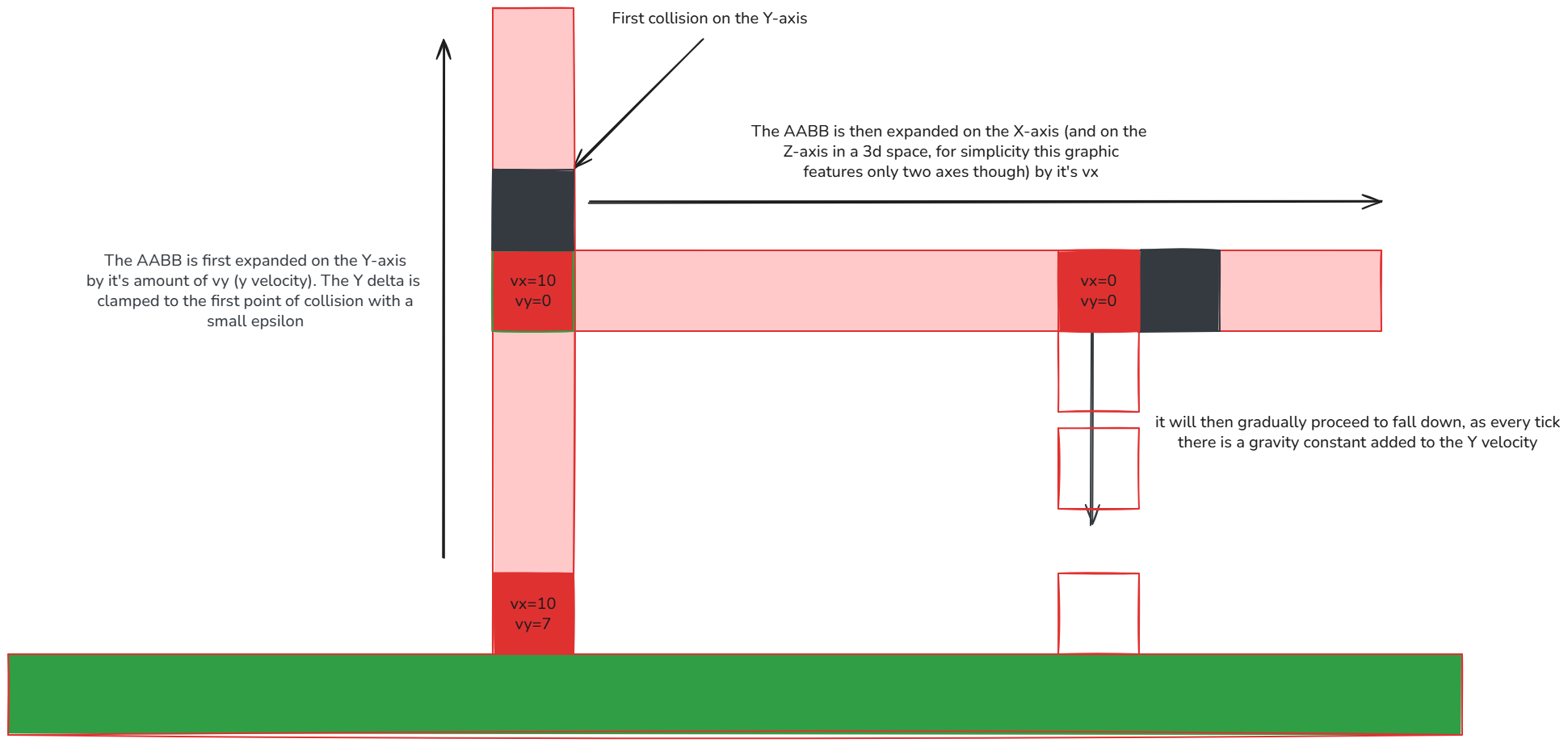
That's what paper's algorithm is supposed to do too, yet it doesn't do it properly.
Vanilla resolves per-axis with an order bias (Y first, then the larger of X/Z). The points of collision (faces) effectively only exist under that order. Consider v = (300, 100, 500) with a solid wall along Z and only a single block along X.
- If resolution checks Z before X: at Δz = 50 we compute tZ = 50 / 500 = 0.1. At that time, X' = X0 + 0.1 * 300 = X0 + 30, which overshoots the X block entirely. Z clamps, X never does, and the leftover vX produces sideways glide.
- If resolution checks Y, then X: at Δx = 20, tX = 20 / 300 ≈ 0.0667 which is less than tZ. X clamps first, zeroing vX. At tZ = 0.1, the interpolated position still intersects the Z wall, so Z clamps as well. Both vX and vZ are cancelled, leaving no glide.
Thus, the static per-axis order (Y -> X -> Z) or dynamic smart ordering (east/west patch) addresses these issues directly by determining the correct points of collision.
East/West patch
Following up on the new collision logic, we have decided to introduce a east/west patch. Due to the way minecraft calculates entity movement, certain cannons would only be able to fire facing north and south. This could be circumvented with a certain type of L-shaped barrel, however, this was hard to implement on pitforge due to the limited space. this patch should eliminate this issue by dynamically determining the order in which to calculate collisions based on the entity's velocity and some other factors.
How it works
In a nutshell, it can be as simple as re-ordering the calculation of collisions on the X- and Z-axis according to the amount of horizontal velocity the entity has.
private Vec3 collide(final Vec3 movement) {
if (movement.equals(Vec3.ZERO)) return movement;
AABB boundingBox = this.getBoundingBox();
final List<VoxelShape> voxels = new ArrayList<>();
final List<AABB> bbs = new ArrayList<>();
// Always Y first, then smaller of X/Z, then the other
List<Axis> order = Math.abs(movement.x) <= Math.abs(movement.z)
? List.of(Axis.Y, Axis.X, Axis.Z)
: List.of(Axis.Y, Axis.Z, Axis.X);
double[] result = new double[3];
for (Axis axis : order) {
double dx = axis == Axis.X ? movement.x : 0.0;
double dy = axis == Axis.Y ? movement.y : 0.0;
double dz = axis == Axis.Z ? movement.z : 0.0;
double c = performCollisions(level, this, dy, dx, dz, boundingBox, voxels, bbs);
result[axis.ordinal()] = c;
boundingBox = boundingBox.move(dx != 0.0 ? c : 0.0, dy != 0.0 ? c : 0.0, dz != 0.0 ? c : 0.0);
}
return new Vec3(result[Axis.X.ordinal()], result[Axis.Y.ordinal()], result[Axis.Z.ordinal()]);
}Where the input movement is the entity's velocity and the return value is the final delta after applying collisions.
On top of that we do some other deterministic calculations to avoid unintended side-effects.
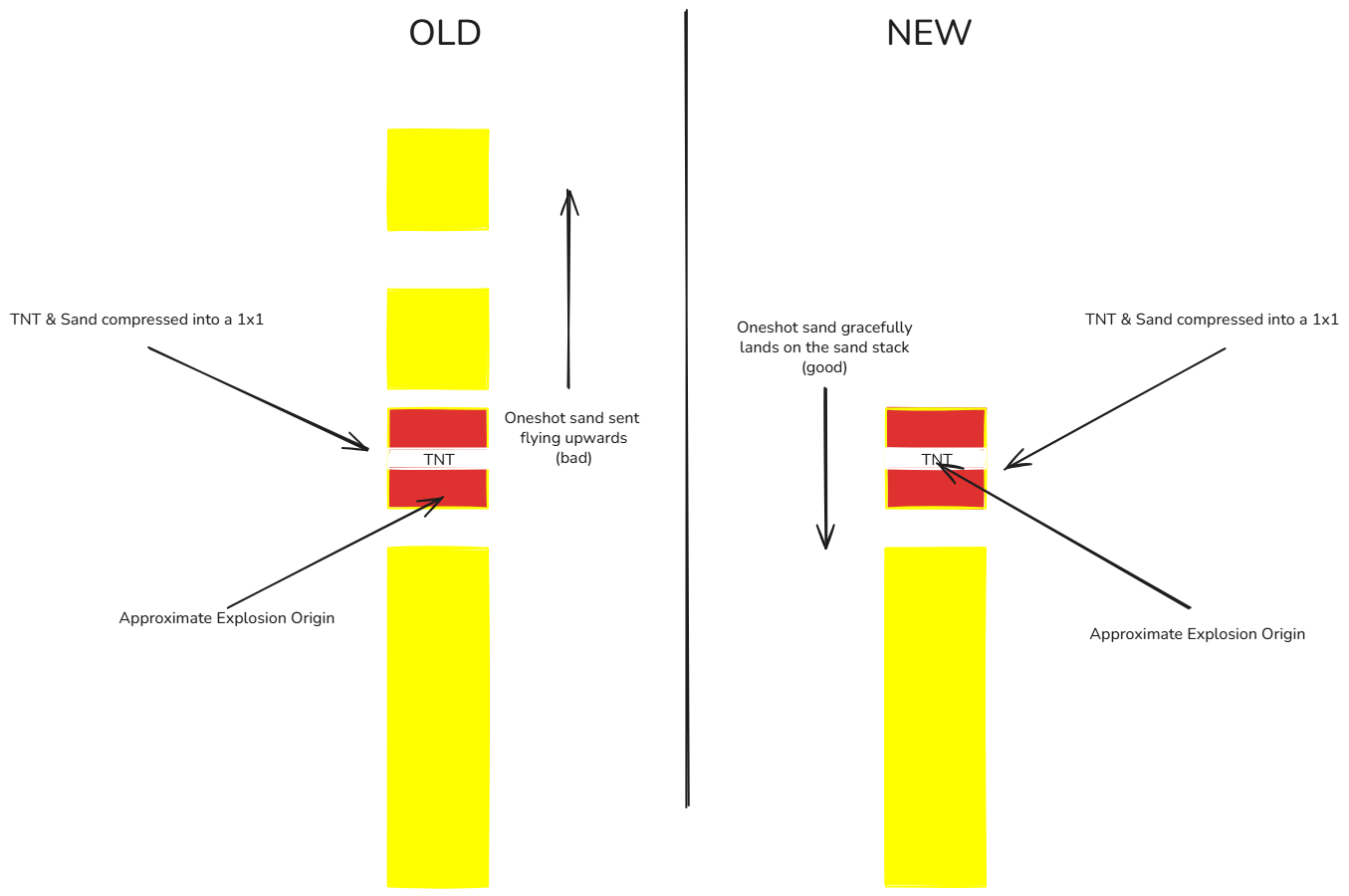
Falling block & TNT head height
For whatever reason, at some point minecraft decided to change the origin of a TNT's explosion to, basically it's lower center. Meaning that if you had sand and tnt compressed into a single block, due to the explosion originating from below the sand it would wrongfully shoot it upwards. This caused the hammer to send one shot sand flying upward instead of it landing on top of the sand stack.
Here’s a 100% accurate side-by-side comparison of how it used to work versus how it works after that patch:
Entity merging - hash-first merging to tame dense entity churn
You can hit surprisingly bad CPU costs when the world floods with small entities (TNT, falling blocks, etc.) just for existing.
ServerLevel creates a tiny per-tick lookup within the entityTickList loop and asks mergeable entities to try merging:
// ServerLevel (tick loop)
final FastEntityLookupTable entityLookup = new FastEntityLookupTable();
this.entityTickList.forEach(entity -> {
if (entity instanceof com.hyphale.minecraft.entity.Mergeable<?> mergeable) {
handleEntityMerge(mergeable, mergeable.getClass(), entityLookup);
}
//...
});The core handler is intentionally simple and fast: compute a compact fingerprint, probe the table, and let the existing entity decide whether to "absorb" the new one.
private boolean handleEntityMerge(Mergeable<?> entity, Class<? extends Mergeable> cls, FastEntityLookupTable lookup) {
long hash = entity.fastHash();
Mergeable<?> candidate = lookup.lookup(cls, hash);
if (candidate != null) {
return candidate.mergeAny(entity);
} else {
lookup.insert(hash, entity);
}
return false;
}Entities opt into this pattern by implementing Mergeable (the contract keeps merge logic where it belongs):
public interface Mergeable<T extends Mergeable<T>> {
T merge(final T other);
boolean mergeAny(final Mergeable<?> other);
void unmerge();
boolean isEssentiallyTheSame(final Object object);
int getChildren();
long fastHash();
}This obviously means that if Mergeable#fastHash returns the same value for two entities, they're considered "essentially the same" and therefore mergeable. Now usually we cannot encode all the data we need to determine uniqueness into a truly unique 64 bit value. But we can keep the probability of collisions quite low whilst still encoding all relevant properties with a simple hash function:
public class PrimedTnt extends Entity implements /*...*/ Mergeable<PrimedTnt> {
@Override
public long fastHash() {
// Encode all relevant values to determine whether two tnt entities can be merged
long result = Integer.toUnsignedLong(getFuse());
result = 31 * result + Double.doubleToRawLongBits(getX());
result = 31 * result + Double.doubleToRawLongBits(getY());
result = 31 * result + Double.doubleToRawLongBits(getZ());
result = 31 * result + getDeltaMovement().hashCode();
result = 31 * result + getBoundingBox().hashCode();
return result;
}
}And the lookup is a tiny typed map (class → hash → entity) with O(1) probes:
public class FastEntityLookupTable {
private Map<Class<?>, Table<?>> tables = new HashMap<>();
public <T> T lookup(final Class<T> clazz, final long id) { ... }
public <T> void insert(final long id, final T value) { ... }
public void clear() { tables.clear(); }
}In a nutshell, 2 entites essentially become one with the parent entity only tracking the amount of children it has, unmerging at just the right moment. What "unmerging" means depends on the entity implementing Mergeable.
It could be as simple as doing:
public class PrimedTnt extends Entity implements /*...*/ Mergeable<PrimedTnt> {
private int children = 0;
// ...
@Override
public void unmerge() {
for (int i = 0; i < this.children; i++) {
PrimedTnt vtnt = this.clone();
vtnt.tick();
}
}
}It's purpose and advantages over neighbor scans
- Neighbor scans can degrade toward O(N^2) in dense clusters (many entities each checking many neighbors).
- This approach performs a single O(1) probe per candidate entity, so merge work is O(N) amortized per tick for mergeable entities.
- Lower CPU: far fewer bounding-box queries, fewer allocations, much less branching in hot loops and generally less entities to tick.
- Practically zero overhead during entity ticking. Merging occurs only after an O(1) lookup has succeeded which is done within a section of code that would run anyways
Caveats
- Correctness relies on a well-designed fastHash() and on mergeAny(...) performing final verification (isEssentiallyTheSame) to handle hash collisions safely.
- Merge semantics (events, stack updates, unmerge() behavior) remain the entity’s responsibility. It's easier to introduce bugs using entity merging.
- The table is tick-local — merges are immediate within the same tick cycle.
Takeaway Entity merging is a pragmatic, low-overhead change: hash-first probes replace expensive local scans, converting worst-case quadratic merge work into linear per-tick behavior while keeping merging semantics under entity control. It’s a small bookkeeping cost for a large reduction in CPU work in crowded scenes.
Performance Optimizations
There are essentially two very hot spots during explosion calculations, one of them being the exposure calculation which fires a ton of rays everywhere and the ray marching to collect blocks.
Exposure
This might be the hottest spot, especially in entity heavy scenes (which is a common occurence when firing a cannon)
Per axis you step withinc = 1 / (2*Δ + 1), where Δ is the box size on that axis.
Samples per axis = ⌊1/inc⌋ + 1 = ⌊2*Δ + 1⌋ + 1.
- If Δ = 1.0 →
inc = 1/3, samples =⌊3⌋ + 1 = 4.
Rays =4 × 4 × 4 = 64. - If Δ ≈ 0.98 (typical TNT/falling block) →
inc ≈ 1/2.96, samples =⌊2.96⌋ + 1 = 3.
Rays =3 × 3 × 3 = 27.
TNT/falling blocks are ~0.98³, which yields 27 rays per entity. Which makes a whopping 2.700.000 for a scene with about 250 explosions and 400 nearby entities (sand, oneshot, slabbust and whatever else) which is a pretty common scenario in cannoning. 2.7m rays, all in a single tick. Even though most of them exit early, having that, along with all the other server logic, run within 50ms is, optimistic to say the least.
Since that's quite a lot of rays, we need to make sure our code runs fast. Though this is largely mitigated by entity merging, we can still make it run a lot faster.
So Paper's implementation of getSeenFriction
private float getSeenFraction(final Vec3 source, final Entity target,
final ca.spottedleaf.moonrise.patches.collisions.ExplosionBlockCache[] blockCache,
final BlockPos.MutableBlockPos blockPos) {
final AABB boundingBox = target.getBoundingBox();
final double diffX = boundingBox.maxX - boundingBox.minX;
final double diffY = boundingBox.maxY - boundingBox.minY;
final double diffZ = boundingBox.maxZ - boundingBox.minZ;
final double incX = 1.0 / (diffX * 2.0 + 1.0);
final double incY = 1.0 / (diffY * 2.0 + 1.0);
final double incZ = 1.0 / (diffZ * 2.0 + 1.0);
if (incX < 0.0 || incY < 0.0 || incZ < 0.0) {
return 0.0f;
}
final double offX = (1.0 - Math.floor(1.0 / incX) * incX) * 0.5 + boundingBox.minX;
final double offY = boundingBox.minY;
final double offZ = (1.0 - Math.floor(1.0 / incZ) * incZ) * 0.5 + boundingBox.minZ;
final ca.spottedleaf.moonrise.patches.collisions.CollisionUtil.LazyEntityCollisionContext context = new ca.spottedleaf.moonrise.patches.collisions.CollisionUtil.LazyEntityCollisionContext(target);
int totalRays = 0;
int missedRays = 0;
for (double dx = 0.0; dx <= 1.0; dx += incX) {
final double fromX = Math.fma(dx, diffX, offX);
for (double dy = 0.0; dy <= 1.0; dy += incY) {
final double fromY = Math.fma(dy, diffY, offY);
for (double dz = 0.0; dz <= 1.0; dz += incZ) {
++totalRays;
final Vec3 from = new Vec3(
fromX,
fromY,
Math.fma(dz, diffZ, offZ)
);
if (!this.clipsAnything(from, source, context, blockCache, blockPos)) {
++missedRays;
}
}
}
}
return (float)missedRays / (float)totalRays;
}Becomes this optimized version which i am going to explain in a second:
private float getSeenFrictionFast(final Vec3 source, final Entity target,
final ca.spottedleaf.moonrise.patches.collisions.ExplosionBlockCache[] block_cache,
final BlockPos.MutableBlockPos block_pos) {
final AABB bb = target.getBoundingBox();
final double min_x = bb.minX, min_y = bb.minY, min_z = bb.minZ;
final double diff_x = bb.maxX - min_x, diff_y = bb.maxY - min_y, diff_z = bb.maxZ - min_z;
final double step_x = 1.0 / (diff_x * 2.0 + 1.0);
final double step_y = 1.0 / (diff_y * 2.0 + 1.0);
final double step_z = 1.0 / (diff_z * 2.0 + 1.0);
if (step_x < 0.0 || step_y < 0.0 || step_z < 0.0) { return 0.0f; }
final int nx = (int)Math.floor(1.0 / step_x) + 1;
final int ny = (int)Math.floor(1.0 / step_y) + 1;
final int nz = (int)Math.floor(1.0 / step_z) + 1;
final double off_x = (1.0 - (nx - 1) * step_x) * 0.5 + min_x;
final double off_y = min_y;
final double off_z = (1.0 - (nz - 1) * step_z) * 0.5 + min_z;
final double scale_x = diff_x * step_x;
final double scale_y = diff_y * step_y;
final double scale_z = diff_z * step_z;
final double to_x = source.x;
final double to_y = source.y;
final double to_z = source.z;
final var ctx = new ca.spottedleaf.moonrise.patches.collisions.CollisionUtil.LazyEntityCollisionContext(target);
final int total = nx * ny * nz;
int misses = 0;
for (int ix = 0; ix < nx; ix++) {
final double from_x = off_x + ix * scale_x;
for (int iy = 0; iy < ny; iy++) {
final double from_y = off_y + iy * scale_y;
for (int iz = 0; iz < nz; iz++) {
final double from_z = off_z + iz * scale_z;
if (!this.clipsAnything(from_x, from_y, from_z, to_x, to_y, to_z, ctx, block_cache, block_pos)) {
misses++;
}
}
}
}
return (float)misses / (float)total;
}
Some changes might seem trivial or overkill, but for a piece of code as hot as that we want to squeeze out every CPU cycle we can get.
So what makes it so much faster?
1. Constant hoisting (outside inner loops)
- Precompute
minX/minY/minZ,diffX/Y/Z,stepX/Y/Z,nx/ny/nz,offX/Z. Eliminates repeated AABB reads and step math (saves ~10–20 FP ops per ray).
2. Integer-indexed sampling
- Iterate
ix=0..nx-1withfromX = offX + ix * (diffX*stepX)
3. Cheaper coordinate math
- Replace
lerp(min,max,t)with a precomputed affine formoff + i*scalewhich also trims a handful of FP ops per axis per ray.
The original function spends a big slice of time not on actual collision geometry, but on:
- Allocating/initializing
ClipContext+ friends, - General pipeline indirections
- Repeated arithmetic/reads it could have hoisted.
The optimized version:
- Removes most allocs
- Replaces general calls with a tight path + cache
- Generally minimizes per-ray math
I haven't quite tested it to the bone yet, but in my tests it yielded anywhere from a 4x-8x performance increase in scenes with a lot of entities.
Collecting Blocks
I don't want to go too in-depth about this as it's not too interesting and paper already handles it quite well, but I'll give you a high level view of what exactly I did to optimize it:
- Avoid unnecessary allocations
- Remove the randomness in the power calculations, saving us anywhere from 5-10ns/ray
- Simplify blast resistence calculation
- Exit early on immediate liquid intersection
Some other changes include but are not limited to:
- RC (Reusable Cobwebs) Sandcomp Fix
- Destroyable water-logged blocks
- Blast resistence overrides
- Explosion radius normalization
- Height nerfs to balance roof cannoning/midairs
- Disable initial spread of TNT upon spawning
- Disable liquid protection for certain block types
- Optimized liquid explosions
- Various other performance optimizations considering Explosions and Entities
However, this isn’t the finale. We’ll keep improving and balancing the physics to deliver a great experience for everyone.
What’s Next?
- New Mechanics
- Duels and Faction Wars
- Capture Points
- Release Date Announcement
Thanks for reading through and as always, see you in the next blog post!